Wer heute über „Sichtbarkeit in LLMs“ spricht, greift reflexartig auf die alte Suchmaschinen-Metapher zurück. Dieses Denkmuster ist verständlich – aber falsch. Es überträgt ein Ordnungsprinzip in eine Welt, in der es keine Ordnung im klassischen Sinn gibt.
Suchmaschinen arbeiten mit Listen, die Prioritäten ausdrücken. Ein „Platz 1“ ist ein explizites, algorithmisch erzeugtes Urteil. Ein LLM dagegen generiert keine Liste, sondern einen Gedankenstrom: Token für Token, basierend auf Wahrscheinlichkeiten, Kontext und interner Wissensverdichtung.
Das bedeutet:
In LLMs existiert kein Ranking. Es existiert nur Erkennen oder Halluzinieren.
Genau hier beginnt das Missverständnis des GEO (Generative Engine Optimization) Denkmodells. Es geht davon aus, dass man Sichtbarkeit messen könne, indem man zählt, wie oft eine Marke im Output erscheint.
Das ist ungefähr so, als würde man die Qualität eines Romans danach beurteilen, wie häufig ein bestimmter Name darin vorkommt – unabhängig davon, ob die Figur als Held oder als Narr dargestellt wird.
Die zentrale Verschiebung:
Sichtbarkeit in LLMs entsteht nicht durch Wettbewerb um Aufmerksamkeit, sondern durch stabile Verankerung im Wissensraum des Modells.
Alles, was darauf verzichtet, diese Verankerung zu prüfen – und stattdessen nur den Output beobachtet –, misst nicht Sichtbarkeit, sondern Zufall.

Die meisten Ansätze der SEO/GEO Industrie scheitern nicht an der Technologie, sondern am Denkmodell. Sie setzen dort an, wo sie sich auskennen: im logikorientierten System der Suchmaschinenoptimierung. Doch genau dieses System existiert in LLMs nicht.
Der zentrale Fehler: Man behandelt ein generatives Modell wie eine Retrieval-Maschine.
- Retrieval-Systeme (klassische Suchmaschinen) bewerten Dokumente gegeneinander. Sie arbeiten mit Signalen, die relative Stärke ausdrücken: Relevanz, Autorität, Aktualität. Das Konzept des „Rankings“ ist die logische Folge dieser Mechanik – eine Auswahl des Besten.
- Generative Modelle hingegen operieren nicht relativ, sondern probabilistisch. Sie wählen keine Quelle „vor“ einer anderen aus. Sie synthetisieren Wahrscheinlichkeiten.
Die entscheidende Unterscheidung:
Eine Antwort entsteht nicht durch Selektion, sondern durch Verdichtung.
Wenn GEO nun versucht, Sichtbarkeit in ChatGPT oder Gemini zu messen, indem es zählt, wie oft eine Marke „im Output vorkommt“, dann misst es Symptome ohne Pathologie. Es beobachtet Erscheinungen, nicht Ursachen.
Das führt zu zwei fatalen Fehlannahmen:
- Die Annahme, dass Erwähnung = Sichtbarkeit sei. Doch eine Marke kann erwähnt werden, obwohl das Modell sie nicht korrekt versteht. Ebenso kann sie fehlen, obwohl eine starke Evidenzlage vorliegt. Erwähnung ist ein Nebenprodukt, kein Indikator.
- Die Annahme, dass Output-Metriken Aussagen über die interne Wissensstruktur erlauben. Tun sie nicht. Ein Modell kann oberflächlich korrekt antworten – während es in der Tiefe falsche Entitäten verknüpft, Quellen ignoriert oder numerisch halluziniert.
Was die GEO-Fraktion misst, ist also lediglich Reaktionsverhalten, nicht Wissensarchitektur. Doch Sichtbarkeit in LLMs entsteht ausschließlich in der Wissensarchitektur.
Genau deshalb werden GEO-Dashboards zwangsläufig zu Diagrammen über den Zufall. Sie aggregieren Antworten, die keine diagnostische Kraft besitzen, und erzeugen daraus Trends, die semantisch leer bleiben. Sie simulieren Messbarkeit, ohne einen messbaren Gegenstand zu haben.
Die Konsequenz:
Wer LLMs mit der Logik der Suchmaschinen analysiert, misst eine Welt, die es so nicht mehr gibt.
Warum klassische Monitoring-Tools nur die Oberfläche messen
Die derzeit verbreiteten Monitoring-Ansätze arbeiten mit einer simplen Logik: Eine Frage wird gestellt, der Output wird analysiert, und die Marke erhält Punkte, wenn sie erwähnt wird.
Das klingt nach Struktur, ist aber methodisch flach. Diese Tools beobachten lediglich Erscheinungen, nicht Mechanismen. Sie messen, was ein Modell sagt – nicht, warum es etwas sagt.
Das Problem liegt nicht im Aufwand, sondern im Objekt selbst:
Der Output eines LLM ist kein stabiler Messgegenstand.
Er ist probabilistisch, kontextabhängig und von zahlreichen Faktoren beeinflusst, die Außenstehende nicht kontrollieren können. Jede Antwort ist eine Momentaufnahme, keine Quelle der Wahrheit.
Drei strukturelle Grenzen machen output-basierte Tools für strategisches Monitoring unbrauchbar:
- Sie erkennen keine Quelle (Blindheit für Evidenz)
Ein Modell kann korrekt antworten, während es sich auf eine falsche oder unzuverlässige Quelle stützt. Der Output wirkt plausibel, doch die interne Beleglogik bleibt unsichtbar. Tools, die nur den Text analysieren, haben keinen Zugang zu dieser Ebene. - Sie erkennen Entitätenfehler nicht als solche (Semantische Blindheit)
Wenn ein Modell einen CEO dem falschen Unternehmen zuordnet oder einen Bond mit einem anderen Coupon verwechselt, erscheint der Output sprachlich einwandfrei – aber in der Sache falsch. Klassische Tools bewerten beides oft gleich positiv, solange das Keyword fällt. - Sie erfassen Präzisionsfehler nicht strukturell (Numerische Blindheit)
Zeitliche Abfolgen, Beträge, Regulatorik, Quoten – das sind die Bereiche, in denen Modelle systematisch scheitern. Doch ein Monitoring, das nur nach Schlagworten scannt, erkennt weder das Problem noch die Ursache.
Der entscheidende Punkt:
Output ist Symptom, nicht Fundament.
Solange Monitoring-Tools nur Symptome messen, bleiben Unternehmen blind für die Frage, die wirklich zählt:
Greift das Modell auf meine strukturierten Daten zu – oder reproduziert es lediglich das Rauschen seiner Trainingsdaten?
Diese Unterscheidung entscheidet über Sichtbarkeit, Korrektheit und letztlich über die digitale Deutungshoheit. Alles andere ist kosmetische Statistik.
Die vier Dimensionen echter AI Visibility
Wenn wir verstehen wollen, wie Sichtbarkeit in LLMs tatsächlich entsteht, müssen wir uns von der Vorstellung lösen, dass der Output ein Abbild des Wissens sei. In der generativen Architektur entsteht Sichtbarkeit nicht auf der Oberfläche der Antwort, sondern im inneren Gefüge der Beleg- und Verknüpfungslogik.
Genau hier setzen die vier Dimensionen an. Sie sind keine abstrakten Kategorien, sondern konkrete Prüfsteine der maschinellen Semantik.
1. Attribution: Der Identitäts-Check
Wird die Marke auch ohne Namensnennung erkannt?
Attribution ist der elementare Sichtbarkeitsanker. Sie beantwortet die Frage: Weiß das Modell, dass ein bestimmter Sachverhalt zu mir gehört – auch dann, wenn ich nicht explizit erwähnt werde?
Ein Modell, das ein Joint Venture, einen Bond oder eine Kennzahl korrekt einem Unternehmen zuordnet, zeigt echte Sichtbarkeit. Ein Modell, das stattdessen einen Wettbewerber nennt, zeigt das Gegenteil: fehlende Verankerung im eigenen Wissensraum. Attribution ist damit nicht nur ein Messpunkt, sondern ein Frühwarnsystem für semantische Unsicherheit.
2. Entitätenauflösung: Der Beziehungs-Check
Hält das Modell den Graph eines Unternehmens stabil?
Halluzinationen entstehen selten aus dem Nichts, sondern aus falsch verknüpften Entitäten. Wenn ein Modell JV-Partner verwechselt, Beteiligungsquoten verschiebt oder Rollen durcheinanderbringt, entsteht ein Antworttext, der sprachlich korrekt wirken kann – aber inhaltlich unbrauchbar ist.
Diese Dimension markiert den entscheidenden Unterschied zwischen:
- „Das Modell hat etwas über mich gehört“ (Training Rauschen)
- „Das Modell hat meine Struktur verstanden“ (Semantische Verankerung)
Nur Letzteres erzeugt nachhaltige Sichtbarkeit.
3. Evidenzqualität: Der Beweis-Check
Kann das Modell belegen, was es behauptet?
Ein LLM, das keine Quelle nennen kann, ist in der Unternehmenskommunikation wertlos. Plausibilität ersetzt Belegbarkeit nicht. Evidenzqualität prüft, ob ein Modell konkrete Dokumente, exakte Datumsangaben oder definierte Reports als Quellen anführen kann.
Eine korrekte Antwort ohne Quelle ist ein Zufallstreffer. Eine korrekte Antwort mit Quelle ist ein Kompetenznachweis.
Sichtbarkeit entsteht immer dort, wo Modelle belegbare Strukturen statt diffuses Trainingswissen nutzen.
4. Temporalität & Numerische Präzision: Der Fakten-Check
Beherrscht das Modell Zeit und Zahlen?
Die Achillesferse aller Modelle liegt in Sequenzen und Mengen. Zeitliche Abläufe, Bilanzsummen, Coupon-Raten – das sind die Punkte, an denen Modelle am häufigsten scheitern, weil sie intern nicht mit Zahlen, sondern mit Textmustern operieren.
Hier entscheidet sich, ob eine Marke im probabilistischen Raum stabil bleibt oder in approximierten Mustern verschwindet.
Die Konsequenz: Sichtbarkeit ist ein Strukturphänomen, kein Marketingphänomen.
Erst wenn alle vier Dimensionen stabil sind, entsteht eine Form von Sichtbarkeit, die über bloße Erwähnungen hinausgeht. Sie zeigt, dass ein Modell nicht rät, sondern verankert ist; nicht approximiert, sondern versteht; nicht textet, sondern belegt.
”Sichtbarkeit in LLMs misst nicht das Ergebnis einer Antwort, sondern die Qualität des Fundaments, aus dem die Antwort entsteht.
Norbert Kathriner
Warum strukturierte Daten das einzige tragfähige Fundament sind
Wenn Modelle Sichtbarkeit nicht über Rankings herstellen, sondern über semantische Verankerung, dann verschiebt sich die Frage: Womit wird diese Verankerung erzeugt?
Texte allein leisten das nicht. Sie sind für Menschen geschrieben – und werden von Maschinen interpretiert. Genau hier entsteht das Problem:
Interpretation ist der Ort des Fehlers.
LLMs sind exzellent darin, sprachliche Muster zu erkennen. Sie sind jedoch nicht dafür gebaut, komplexe Faktenstrukturen stabil zu speichern. Zeitliche Sequenzen, Rollen, Beteiligungen, Quoten – all das geht in unstrukturierten Texten leicht verloren oder wird im Training verzerrt.
Damit ein Modell zuverlässige Aussagen über ein Unternehmen treffen kann, muss es etwas erhalten, das nicht interpretierbar ist: eine maschinenlesbare Wahrheitsschicht.
Diese Wahrheitsschicht entsteht durch strukturierte Daten (JSON-LD, Schema.org) – nicht als SEO-Beiwerk, sondern als semantisches Rückgrat der Marke. Sie erfüllen drei Funktionen, die kein Fließtext leisten kann:
1. Sie eliminieren Interpretationsspielräume
Ein Datum wie „18.07.2025“ oder ein Betrag wie „923 Mio USD“ wird im Modell nicht länger mühsam aus einem Satz extrahiert, sondern als eigenständige, eindeutig typisierte Information verarbeitet. Das reduziert Fehler, schützt vor Halluzinationen und schafft eine Präzision, die in Textform niemals garantiert werden kann.
2. Sie machen Beziehungen explizit
Ein Joint Venture ist für eine Maschine keine Geschichte, sondern eine Relation: Zwei Organisationen, ein Startdatum, Beteiligungsquoten, Rollen. JSON-LD schreibt diese Beziehungen nicht in Sätzen nieder, sondern im Graphen. Ein Graph ist für ein Modell kein literarisches Konstrukt, sondern ein struktureller Fakt. Damit entsteht ein Mechanismus, der den Kern jeder LLM-Sichtbarkeit beschreibt:
Entitäten müssen nicht mehr erraten werden – sie werden erkannt.
3. Sie liefern Referenzen, die belegbar sind
Eine Quelle, die ein Modell nicht benennen kann, existiert für die Praxis nicht. Strukturierte Daten machen aus Dokumenten referenzierbare Objekte: Reports, Events, Datasets. Damit wird aus der Abfrage eines Sachverhalts ein nachprüfbarer Schluss. Evidenz wird nicht erhofft, sondern technisch erzwungen.
Die logische Konsequenz
Wer Sichtbarkeit in LLMs ernsthaft steuern will, muss eine Ebene betreten, die jenseits des traditionellen Marketings liegt. Nicht Storytelling, sondern maschinelle Semantik entscheidet darüber, wie eine Marke in probabilistischen Systemen erscheint.
Strukturierte Daten sind kein „Zusatz“ – sie sind die einzige stabile Schnittstelle zwischen Unternehmenskommunikation und generativen Modellen.
- Ohne sie bleibt jede Antwort ein statistisches Produkt.
- Mit ihnen wird jede Antwort ein struktureller Schluss.
Deshalb gilt: AI Visibility entsteht nicht durch Optimierung des Textes, sondern durch Architektur der Wahrheit.
Wie professionelles Monitoring aussehen muss: Das Eisberg-Modell
Wenn LLMs keine Dokumente ranken, sondern Wahrscheinlichkeiten verdichten, dann lässt sich Sichtbarkeit nicht durch das bloße Beobachten des Outputs messen. Der Output ist lediglich die sichtbare Spitze des Eisbergs – und damit der am wenigsten verlässliche Teil des Systems.
Professionelles Monitoring beginnt dort, wo die Oberfläche endet: beim Fundament der Antwortentstehung. Dafür benötigen wir zwei komplementäre Fragetechniken, die gemeinsam ein vollständiges Bild ergeben.
1. User-Prompts: Die Sichtbarkeit an der Oberfläche
Simulieren die Realität: kurz, natürlich, unvollständig.
Sie beantworten die Frage: Findet das Modell mein Unternehmen überhaupt? Eine korrekte Antwort zeigt, dass die Marke im Wissensraum präsent ist. Eine falsche Antwort zeigt, dass sie im semantischen Nebel verschwindet.
- Typisch: Unscharfe Fragen, fehlender Kontext, markenfreie Formulierungen („Wer plant ein JV in Indien?“).
- Ihr Wert: Sie zeigen, wie das Modell im Alltag reagiert – unter realen Nutzungsszenarien.
- Ihre Grenze: Sie zeigen nicht, warum das Modell so reagiert.
2. Forensiker-Prompts: Die Sichtbarkeit im Fundament
Zielen nicht auf das, was das Modell sagt, sondern darauf, wie es dorthin gelangt ist.
Sie sind präzise, strukturiert und evidenzorientiert. Sie prüfen Fragen wie: Kann das Modell die Quelle nennen? Stimmen Beträge und Verhältnisse? Sind Rollen korrekt aufgelöst?
- Typisch: Exakte Datenabfragen, Forderung nach Quellenzitaten, Rekonstruktion von Beziehungen.
- Ihr Wert: Sie zeigen nicht nur Fehler – sie zeigen Mechanismen.
Und Mechanismen sind das Einzige, was in der AI Visibility langfristig zählt.
Warum beide Welten notwendig sind
Ein Unternehmen, das nur User-Prompts testet, sieht nur Symptome. Ein Unternehmen, das nur Forensiker-Prompts testet, sieht nur das Labor. Erst die Kombination ergibt ein vollständiges Bild:
- User-Prompts prüfen Attribution: Wird das Unternehmen spontan erkannt?
- Forensiker-Prompts prüfen Evidenz: Wird es korrekt verstanden und belegt?
Wenn eine der beiden Welten instabil ist, entsteht eine Scheinsichtbarkeit, die in entscheidenden Momenten versagt – etwa bei komplexen Finanzfragen oder Krisenkommunikation.
Wie LLMs entscheiden, wer zitiert wird
Sichtbarkeit in KI-Systemen entsteht nicht durch Positionen, sondern durch erkennbare Entitäten und belastbare Evidenz.
Der Artikel „Entity Recognition und Evidence Weighting“ zeigt, nach welchen Kriterien Sprachmodelle Quellen auswählen – und warum Struktur wichtiger ist als Reichweite.
Zusammenfassung: Das Eisberg-Modell
Oberfläche (User-Prompts)
- Fokus: Was das Modell sagt.
- Status: Sichtbar, aber unzuverlässig.
- Entscheidung: Hier zeigt sich, ob die Marke spontan erscheint.
Fundament (Forensiker-Prompts)
- Fokus: Warum das Modell es sagt.
- Status: Unsichtbar, aber determinierend.
- Entscheidung: Hier zeigt sich, ob die Marke verstanden ist.
Das Monitoring muss beides messen: die spontane Orientierung und die strukturelle Beweisfähigkeit. Ohne diese Dualität bleibt Sichtbarkeit ein Zufallsprodukt.
Warum Rankings tot sind – und was sie ersetzt
Viele aktuelle Debatten über „AI SEO“ oder „GEO“ klammern sich an das vertraute Konzept des Rankings, weil es ein klares, einfaches Versprechen vermittelt: Wer sich optimiert, steigt nach oben; wer nichts tut, fällt nach unten.
Doch dieses Versprechen hat seinen Gegenstand verloren. In generativen Modellen gibt es weder eine Liste, noch eine Position, noch ein Oben oder Unten.
Die Vorstellung eines Rankings ist nicht falsch – sie ist bedeutungslos.
Was ersetzt das Ranking? Eine neue Metrik, die nicht auf Konkurrenz basiert, sondern auf Kohärenz:
Wie stabil ist die interne Repräsentation eines Unternehmens innerhalb des Modells?
Statt Rankings zählen vier strukturelle Eigenschaften:
1. Stabilität der Attribution
Die Frage ist nicht: „Werde ich erwähnt?“, sondern: „Werde ich auch ohne Erwähnung erkannt?“
Das ist der fundamentale Unterschied zwischen Sichtbarkeit und Rauschen. Ein Modell, das Sachverhalte spontan dem richtigen Unternehmen zuordnet, zeigt eine echte, tief verankerte Kenntnis. Alles andere ist statistische Willkür.
2. Integrität der Entitätenlogik
Sichtbarkeit entsteht nur, wenn ein Modell die interne Struktur eines Unternehmens versteht: Produkte, Rollen, Organisationseinheiten, Partner.
Ein Modell, das Entitäten verwechselt, ist nicht weniger sichtbar – es ist falsch sichtbar. Eine Marke, die falsch verstanden wird, ist im praktischen Ergebnis nicht präsent, sondern verzerrt.
3. Konsistenz der Evidenz
Sichtbarkeit bedeutet heute nicht, aufzutauchen, sondern belegt aufzutauchen.
Eine Antwort ohne Quelle ist ein semantisches Artefakt – ein zufälliges, plausibles Fragment. Eine Antwort mit Quelle zeigt: Das Modell greift auf die bereitgestellte Wahrheitsschicht zu.
Es rekonstruiert nicht, es referenziert. Das ist der qualitative Sprung zwischen „erwähnt werden“ und „wahrgenommen werden“.
4. Exaktheit von Zeit und Zahlen
Generative Modelle können nur dann als glaubwürdig gelten, wenn sie zeitliche Abläufe und numerische Werte korrekt wiedergeben. Die Exaktheit der Fakten ist die härteste Form der Sichtbarkeit – und die differenzierendste.
Die neue Metrik: Quellenverankerung statt Platzierung
Wenn wir Ranking durch Quellenverankerung ersetzen, verschiebt sich die gesamte Logik:
- Weg von Wettbewerbssignalen → Hin zu struktureller Identität.
- Weg von Messung des Outputs → Hin zu Messung der semantischen Grundlagen.
Sichtbarkeit ist kein relativer Zustand („Ich bin oben“), sondern ein absoluter Zustand: Das Modell versteht mich – oder es versteht mich nicht.
Daraus folgt ein radikaler, aber unausweichlicher Satz:
Das Konzept des Rankings ist in LLMs nicht nur überholt, sondern epistemisch unbrauchbar.
AI Visibility Angebot
Sichtbar für Menschen. Sichtbar für Maschinen.
Wenn KI entscheidet, was sichtbar ist, hilft keine Kampagne und kein Corporate Design. Nur Struktur.
Fazit: In LLMs existiert kein Ranking. AI Visibility ist Infrastruktur, nicht Marketing
Wenn man die Mechanik generativer Modelle ernst nimmt, bleibt am Ende eine einfache, aber folgenreiche Einsicht: Sichtbarkeit in LLMs ist kein Wettbewerb um Aufmerksamkeit, sondern ein Wettbewerb um Wahrheit.
Nicht darum, wie laut man spricht, sondern darum, wie präzise man strukturiert. Unternehmen, die AI Visibility als Fortsetzung des Suchmaschinenmarketings betrachten, missverstehen die Lage. Sie optimieren den Text – obwohl das Modell die Struktur braucht. Sie zählen Erwähnungen – obwohl das Modell Belege benötigt.
AI Visibility ist deshalb keine kommunikative Disziplin, sondern eine architektonische. Sie gehört dorthin, wo Systeme definiert werden, nicht dorthin, wo Kampagnen geplant werden.
In diesem Verständnis wird der Kern sichtbar:
Strukturierte Daten sind kein Add-on. Sie sind die operative Wahrheitsschicht eines Unternehmens.
Erst diese Wahrheitsschicht ermöglicht, dass generative Modelle konsistent, belegbar und präzise über eine Marke sprechen – und nicht über approximierte Muster ihrer Trainingsdaten. Sichtbarkeit ist damit kein Kommunikationsversprechen, sondern ein Integritätsversprechen:
- Ein Modell kann nur dann korrekt sein, wenn die Quelle korrekt ist.
- Ein Modell kann nur dann vertrauenswürdig sein, wenn die Fakten stabil sind.
- Ein Modell kann nur dann sichtbar machen, was existiert, wenn dieses Existierende maschinenlesbar gemacht wurde.
”Hören wir deshalb auf, Rankings zu zählen. Fangen wir an, Wahrheiten zu verankern. Denn im Raum der LLMs gewinnt nicht der Lauteste, sondern der Präziseste. Und nicht der, der am meisten publiziert, sondern der, der die klarste Struktur hinterlässt.
Norbert Kathriner
Linktipps
Wie LLMs entscheiden wer zitiert wird
Entity Recognition und Evidence Weighting
Mit Entitäten zu maschinenlesbaren Strukturen für AI Visibility
Struktur schlägt Ranking: Architekturprinzipien für AI Visibility jenseits von SEO
Monitoring Tools
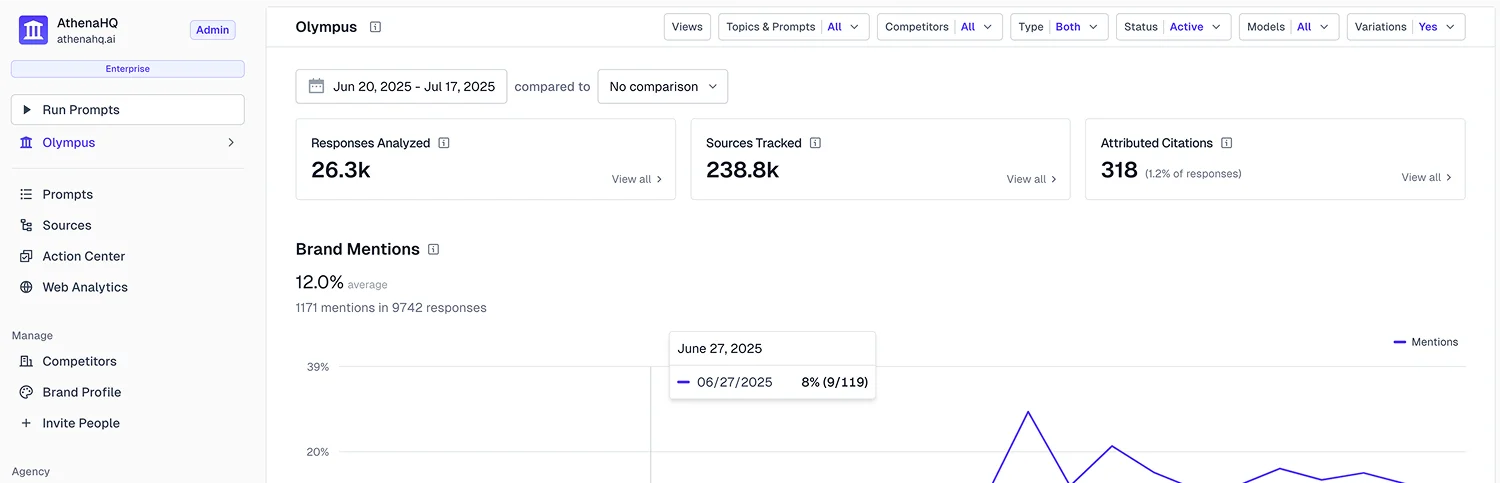
Für das Monitoring nutzen wir zwei externe Tools – Peekaboo und Athena. Beide arbeiten, wie viele Systeme im Markt, noch mit den traditionellen Interpretationslogiken generativer Modelle. Dennoch sind die Messreihen wertvoll: Sie machen Abweichungen sichtbar, zeigen Brüche in der Attribution und geben Hinweise auf Stabilität und Drift. Entscheidend ist nicht die Interpretation der Tools, sondern die Struktur der Rohdaten.
Peekaboo
https://www.aipeekaboo.com/
Athena
https://www.athenahq.ai/