Anyone who talks about “visibility in LLMs” today reflexively falls back on the old search engine metaphor. This way of thinking is understandable – but wrong. It transfers a principle of order into a world in which there is no order in the classic sense.
Search engines work with lists that express priorities. A “rank 1” is an explicit, algorithmically generated judgment. An LLM, on the other hand, does not generate a list, but a stream of thought: token by token, based on probabilities, context and internal knowledge aggregation.
This means:
There is no ranking in LLMs. There is only recognition or hallucination.
This is where the misunderstanding of the GEO (Generative Engine Optimization) model begins. It assumes that visibility can be measured by counting how often a brand appears in the output.
It’s a bit like judging the quality of a novel by how often a certain name appears in it – regardless of whether the character is portrayed as a hero or a fool.
The central shift:
Visibility in LLMs does not arise through competition for attention, but through stable anchoring in the knowledge space of the model.
Anything that refrains from checking this anchoring – and instead only observes the output – does not measure visibility, but coincidence.

Most approaches in the SEO/GEO industry fail not because of the technology, but because of the way they think. They start where they know their way around: in the logic-oriented system of search engine optimization. But it is precisely this system that does not exist in LLMs.
The central mistake is to treat a generative model like a retrieval machine.
- Retrieval systems (classic search engines) evaluate documents against each other. They work with signals that express relative strength: relevance, authority, topicality. The concept of “ranking” is the logical consequence of this mechanism – a selection of the best.
- Generative models, on the other hand, do not operate relatively, but probabilistically. They do not select one source “before” another. They synthesize probabilities.
The decisive distinction:
An answer is not created through selection, but through summarization.
Now, when GEO tries to measure visibility in ChatGPT or Gemini by counting how often a brand “appears in the output”, it is measuring symptoms without pathology. It observes phenomena, not causes.
This leads to two fatal misconceptions:
- The assumption that mention = visibility. However, a marker can be mentioned even though the model does not understand it correctly. It can also be absent even though there is strong evidence. Mention is a by-product, not an indicator.
- The assumption that output metrics allow statements to be made about the internal knowledge structure. They do not. A model can answer superficially correctly – while in depth it links wrong entities, ignores sources or hallucinates numerically.
What the GEO faction measures is therefore only reaction behavior, not knowledge architecture. But visibility in LLMs arises exclusively in the knowledge architecture.
This is precisely why GEO dashboards inevitably become diagrams about chance. They aggregate answers that have no diagnostic power and generate trends that remain semantically empty. They simulate measurability without having a measurable object.
The consequence:
Anyone who analyzes LLMs using the logic of search engines is measuring a world that no longer exists.
Why classic monitoring tools only measure the surface
The currently widespread monitoring approaches work with a simple logic: a question is asked, the output is analyzed, and the brand receives points if it is mentioned.
That sounds like structure, but it is methodologically flat. These tools only observe phenomena, not mechanisms. They measure what a model says – not why it says something.
The problem is not the expense, but the object itself:
The output of an LLM is not a stable measurement object.
It is probabilistic, context-dependent and influenced by numerous factors that outsiders cannot control. Every answer is a snapshot, not a source of truth.
Three structural limitations make output-based tools useless for strategic monitoring:
- You do not recognize a source (blindness to evidence)
A model can answer correctly while relying on an incorrect or unreliable source. The output seems plausible, but the internal evidence logic remains invisible. Tools that only analyze the text do not have access to this level. - They do not recognize entity errors as such (semantic blindness)
If a model assigns a CEO to the wrong company or confuses a bond with another coupon, the output appears linguistically correct – but incorrect in the matter. Classic tools often rate both equally positively as long as the keyword is used. - They do not capture precision errors structurally (numerical blindness)
Time sequences, amounts, regulations, quotas – these are the areas in which models systematically fail. But monitoring that only scans for buzzwords recognizes neither the problem nor the cause.
The key point:
Output is a symptom, not a foundation.
As long as monitoring tools only measure symptoms, companies remain blind to the question that really matters:
Does the model access my structured data – or does it merely reproduce the noise of its training data?
This distinction determines visibility, correctness and ultimately the digital sovereignty of interpretation. Everything else is cosmetic statistics.
The four dimensions of true AI visibility
If we want to understand how visibility actually arises in LLMs, we have to move away from the idea that the output is an image of the knowledge. In generative architecture, visibility is not created on the surface of the answer, but in the inner structure of the document and linking logic.
This is precisely where the four dimensions come in. They are not abstract categories, but concrete touchstones of machine semantics.
1. attribution: the identity check
Will the brand be recognized even without a name?
Attribution is the elementary visibility anchor. It answers the question: Does the model know that a certain fact belongs to me – even if I am not explicitly mentioned?
A model that correctly assigns a joint venture, a bond or a key figure to a company shows real visibility. A model that names a competitor instead shows the opposite: a lack of anchoring in its own knowledge space. Attribution is therefore not just a measuring point, but an early warning system for semantic uncertainty.
2. entity resolution: the relationship check
Does the model keep a company’s graph stable?
Hallucinations rarely arise from nothing, but from incorrectly linked entities. If a model mixes up JV partners, shifts participation quotas or confuses roles, the result is a response text that may appear linguistically correct – but is useless in terms of content.
This dimension marks the decisive difference between:
- “The model heard something about me” (training noise)
- “The model has understood my structure” (semantic anchoring)
Only the latter generates sustainable visibility.
3. quality of evidence: the evidence check
Can the model prove what it claims?
An LLM that cannot name a source is worthless in corporate communications. Plausibility does not replace verifiability. Evidence quality checks whether a model can cite specific documents, exact dates or defined reports as sources.
A correct answer without a source is a random hit. A correct answer with a source is a proof of competence.
Visibility always arises where models use verifiable structures instead of diffuse training knowledge.
4. temporality & numerical precision: the fact check
Does the model control time and numbers?
The Achilles heel of all models lies in sequences and quantities. Time sequences, balance sheet totals, coupon rates – these are the points at which models most frequently fail because they do not operate internally with numbers, but with text patterns.
This determines whether a marker remains stable in probabilistic space or disappears in approximated patterns.
The consequence: visibility is a structural phenomenon, not a marketing phenomenon.
Only when all four dimensions are stable does a form of visibility emerge that goes beyond mere mentions. It shows that a model does not guess, but is anchored; does not approximate, but understands; does not text, but proves.
”Visibility in LLMs does not measure the result of an answer, but the quality of the foundation from which the answer arises.
Norbert Kathriner
Why structured data is the only viable foundation
If models do not create visibility via rankings, but via semantic anchoring, then the question shifts: How is this anchoring created?
Texts alone cannot do this. They are written for humans – and are interpreted by machines. This is precisely where the problem arises:
Interpretation is the place of error.
LLMs are excellent at recognizing linguistic patterns. However, they are not built to store complex fact structures in a stable way. Temporal sequences, roles, participations, quotas – all this is easily lost in unstructured texts or distorted during training.
In order for a model to make reliable statements about a company, it must contain something that cannot be interpreted: a machine-readable layer of truth.
This layer of truth is created by structured data (JSON-LD, Schema.org) – not as an SEO add-on, but as the semantic backbone of the brand. They fulfill three functions that no continuous text can perform:
1. you eliminate room for interpretation
A date such as “18.07.2025” or an amount such as “923 million USD” is no longer laboriously extracted from a sentence in the model, but processed as independent, clearly typed information. This reduces errors, protects against hallucinations and creates a level of precision that can never be guaranteed in text form.
2. you make relationships explicit
For a machine, a joint venture is not a story, but a relationship: two organizations, a start date, participation quotas, roles. JSON-LD does not record these relationships in sentences, but in graphs. A graph is not a literary construct for a model, but a structural fact. This creates a mechanism that describes the core of every LLM visibility:
Entities no longer have to be guessed – they are recognized.
3. you provide references that are verifiable
A source that cannot name a model does not exist in practice. Structured data turns documents into referenceable objects: Reports, events, datasets. This turns the query of a fact into a verifiable conclusion. Evidence is not hoped for, but technically enforced.
The logical consequence
If you want to seriously control visibility in LLMs, you have to enter a level that lies beyond traditional marketing. It is not storytelling but machine semantics that determines how a brand appears in probabilistic systems.
Structured data is not an “add-on” – it is the only stable interface between corporate communication and generative models.
- Without them, every answer remains a statistical product.
- With them, every answer becomes a structural conclusion.
Therefore, AI Visibility is not created by optimizing the text, but by the architecture of truth.
What professional monitoring should look like: The iceberg model
If LLMs do not rank documents, but rather summarize probabilities, then visibility cannot be measured by simply observing the output. The output is merely the visible tip of the iceberg – and therefore the least reliable part of the system.
Professional monitoring begins where the surface ends: at the foundation of the answer generation. To do this, we need two complementary questioning techniques that together provide a complete picture.
1. user prompts: visibility on the surface
Simulate reality: briefly, naturally, incompletely.
They answer the question: Does the model find my company at all? A correct answer shows that the brand is present in the knowledge space. An incorrect answer shows that it disappears into the semantic fog.
- Typical: vague questions, lack of context, unbranded formulations (“Who is planning a JV in India?”).
- Their value: they show how the model reacts in everyday life – under real-life usage scenarios.
- Their limit: They do not show why the model reacts in this way.
2. forensic prompts: visibility in the foundation
Aim not at what the model says, but at how it got there.
They are precise, structured and evidence-oriented. They examine questions such as: Can the model name the source? Are the amounts and ratios correct? Are roles correctly resolved?
- Typical: exact data queries, demand for source citations, reconstruction of relationships.
- Their value: they don’t just show mistakes – they show mechanisms.
And mechanisms are the only thing that counts in AI Visibility in the long term.
Why both worlds are necessary
A company that only tests user prompts only sees symptoms. A company that only tests forensic prompts only sees the lab. Only the combination provides a complete picture:
- Check user prompts Attribution: Is the company recognized spontaneously?
- Forensic prompts check evidence: Is it correctly understood and substantiated?
If one of the two worlds is unstable, the result is a false visibility that fails at crucial moments – for example in complex financial issues or crisis communication.
How LLMs decide who is cited
Visibility in AI systems is not created by positions, but by recognizable entities and reliable evidence.
The article “Entity Recognition and Evidence Weighting” shows the criteria by which language models select sources – and why structure is more important than range.
Summary: The iceberg model
User interface (user prompts)
- Focus: What the model says.
- Status: Visible, but unreliable.
- Decision: This shows whether the brand appears spontaneous.
Foundation (forensic prompts)
- Focus: Why the model says so.
- Status: Invisible, but determining.
- Decision: This shows whether the brand is understood.
Monitoring must measure both: spontaneous orientation and structural evidence. Without this duality, visibility remains a product of chance.
Why rankings are dead – and what replaces them
Many current debates about “AI SEO” or “GEO” cling to the familiar concept of ranking because it conveys a clear, simple promise: If you optimize, you rise to the top; if you do nothing, you fall to the bottom.
But this promise has lost its object. In generative models, there is neither a list, nor a position, nor a top or bottom.
The idea of a ranking is not wrong – it is meaningless.
What replaces the ranking? A new metric that is not based on competition, but on coherence:
How stable is the internal representation of a company within the model?
Instead of rankings, four structural characteristics count:
1. stability of attribution
The question is not: “Will I be mentioned?”, but: “Will I be recognized even without being mentioned?”
This is the fundamental difference between visibility and noise. A model that spontaneously assigns facts to the right company demonstrates genuine, deep-rooted knowledge. Everything else is statistical arbitrariness.
2. integrity of the entity logic
Visibility only arises when a model understands the internal structure of a company: products, roles, organizational units, partners.
A model that confuses entities is no less visible – it is falsely visible. A brand that is misunderstood is not present in the practical result, but distorted.
3. consistency of the evidence
Visibility today does not mean showing up, but showing up occupied.
An answer without a source is a semantic artifact – a random, plausible fragment. An answer with a source shows: The model accesses the layer of truth provided.
It does not reconstruct, it references. This is the qualitative leap between “being mentioned” and “being perceived”.
4. exactness of time and numbers
Generative models can only be considered credible if they correctly reproduce temporal sequences and numerical values. The accuracy of the facts is the hardest form of visibility – and the most differentiating.
The new metric: source anchoring instead of placement
If we replace ranking with source anchoring, the entire logic shifts:
- Away from competitive signals → towards structural identity.
- Away from measuring the output → towards measuring the semantic foundations.
Visibility is not a relative state (“I am on top”), but an absolute state: the model understands me – or it doesn’t understand me.
This leads to a radical but unavoidable sentence:
The concept of ranking in LLMs is not only outdated, but epistemically useless.
AI Visibility offer
Visible to people. Visible for machines.
When AI decides what is visible, no campaign or corporate design will help. Only structure.
Conclusion: There is no ranking in LLMs. AI Visibility is infrastructure, not marketing
If you take the mechanics of generative models seriously, you end up with a simple but momentous insight: visibility in LLMs is not a competition for attention, but a competition for truth.
It’s not about how loud you speak, but about how precisely you structure. Companies that see AI Visibility as a continuation of search engine marketing are misunderstanding the situation. They optimize the text – even though the model needs the structure. They count mentions – even though the model needs evidence.
AI Visibility is therefore not a communicative discipline, but an architectural one. It belongs where systems are defined, not where campaigns are planned.
This understanding reveals the core:
Structured data is not an add-on. It is the operational truth layer of a company.
Only this layer of truth enables generative models to speak consistently, verifiably and precisely about a brand – and not about approximated patterns of its training data. Visibility is therefore not a promise of communication, but a promise of integrity:
- A model can only be correct if the source is correct.
- A model can only be trustworthy if the facts are stable.
- A model can only make visible what exists if this existence has been made machine-readable.
”So let's stop counting rankings. Let's start anchoring truths. Because in the LLM space, it's not the loudest who wins, but the most precise. And not the one who publishes the most, but the one who leaves the clearest structure.
Norbert Kathriner
Link tips
How LLMs decide who gets cited
Entity Recognition and Evidence Weighting
Using entities to create machine-readable structures for AI Visibility
Structure beats ranking: architectural principles for AI Visibility beyond SEO
Monitoring tools
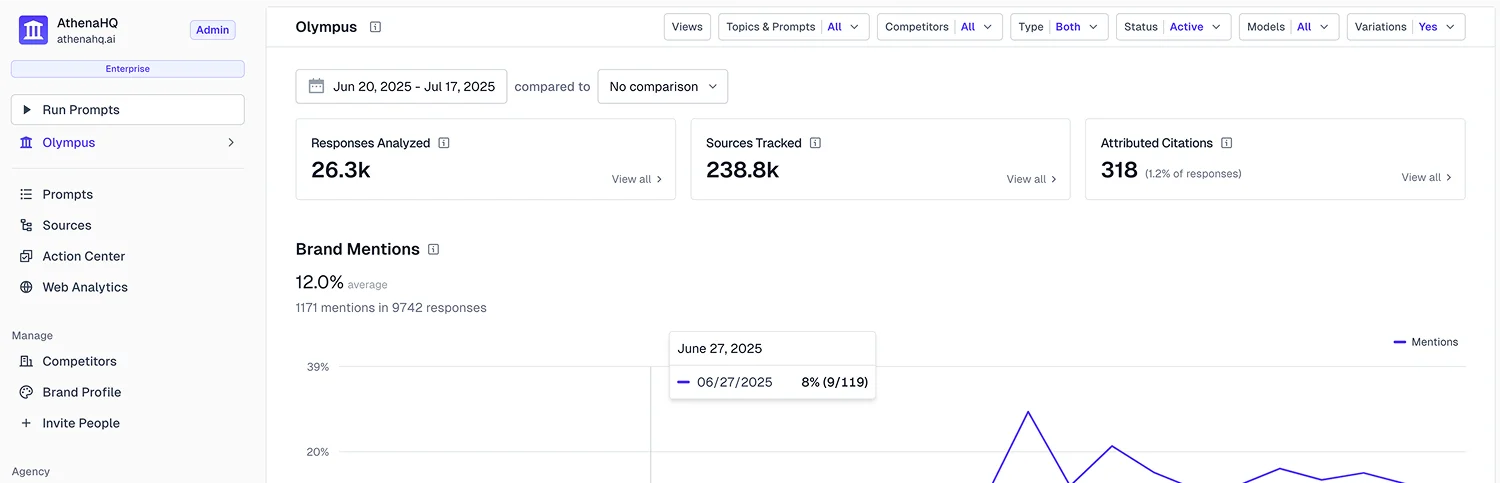
We use two external tools for monitoring – Peekaboo and Athena. Like many systems on the market, both still work with the traditional interpretation logic of generative models. Nevertheless, the measurement series are valuable: they make deviations visible, show breaks in attribution and provide indications of stability and drift. The decisive factor is not the interpretation of the tools, but the structure of the raw data.
Peekaboo
https://www.aipeekaboo.com/
Athena
https://www.athenahq.ai/